TECH VALLEY#4グロースハックパーティ! イベントレポ
geechs, vasily, Willgate, UZABASEの人が公演するイベント、TECH VALLEYグロースハックパーティーに行ってきました。
TECH VALLEYというのはgeechsという会社がやっている技術イベントのことで、
過去にもいろいろな会社のエンジニアやディレクターの方を呼んで公演をしてもらっているイベントだそうです。
今回はそれのグロースハック版で、vasilyやUZABASEといった個人的にかなりいいと思っているアプリやサービスを作っている会社の人たちが登壇するということで、参加することにしました。
学生時代に既存のサイトのUIの改善・実装をやったことはあったけど、成果も出せず悔しい思いをしたので、何か知見が得られるといいなと思っていました。
特にサービスができあがって数年経ったフェーズで行うグロースハックとサービス立ち上げ直前からサービス立ち上げ直後のプロダクトマーケットフィットといわれる部分で行うグロースハックはほぼ別物といってよく、立ち上げ前からサービスが軌道に乗るに至るまでの過程をどう詰めていくかというところに具体的なイメージがわかなかったため、講演ではそこらへんの話が聞ければいいなと思っていました。
参加からだいぶ時間が経ってしまったけど、内容はかなり衝撃的でグロースハックに興味がある人はもちろん、これからサービス・事業を立ち上げようという人や、何かアプリを作ってみたいという人まで勉強になる内容だと思ったので、レポートを作成しました。
4社それぞれの人がディレクター、エンジニアなど様々な立場から会社でやっている手法や技術、マインドセットなどを説明してくださりとても興味深かったです。
ただ、今回は中でも一番印象に残った(自分にとってタイムリーな話題だった)Vasilyの梶谷さんのお話を要約していこうと思います。
残りの3社の方の講演については、需要がありそうだったら書き起こそうと思います(コメントか何か残してください)。
もしグロースハックとはなんぞや、というかたがいらっしゃいましたら、下記記事を参照してください。(というより、ググッた方がわかりやすい答えが見つかると思います)
http://suidenoti.hatenablog.com/entry/2015/04/26/225955
残りの3社の方の講演については、需要がありそうだったら書き起こそうと思います(コメントか何か残してください)。
もしグロースハックとはなんぞや、というかたがいらっしゃいましたら、下記記事を参照してください。(というより、ググッた方がわかりやすい答えが見つかると思います)
http://suidenoti.hatenablog.com/entry/2015/04/26/225955
イベント要約
梶谷さんいわく、グロースハックをする上で下記2点をまず考える必要があるということでした。すなわち、
・マクロレベルの話
自分のサービスが今どのフェーズ(AARRRモデルでどこを重視してやっていくべきところにあるのか)
どのフェーズにいることがわかったら実際にどのKPIを見ていけばいいのか
・ミクロレベルの話
各フェーズで具体的にどういった施策・計測を行えばいいのか
AARRRモデルで一体なにをすればいいのか
といった点です。
マクロ・ミクロの内容についてそれぞれ要約していきます。
グロースハックのマクロレベル
第一声でAARRRモデルをA→A→R→R→Rの順番でやろうとすると確実に失敗するという主張から始まりました。
AARRRモデルは着手すべき順番で並べているのではなく、あくまで顧客視点でどのように行動が変化しているか時系列で並べているにすぎない。したがって、プロダクトをこの順番で成長させようとすると100%失敗する、ということだそうです。
AARRRモデルを順番通りやる最大の問題点として、
・存在しない課題を解決しようとすると製品にコストを使ってしまう
・継続されない製品にコストを使ってしまう
・収益を全く産まないコストに時間を使ってしまう
ということが挙げられ、正しいグロースの順番は下記のARRRAモデル、すなわち
アクティベーション(Activation) そもそもその価値は求められているか、初回訪問時にしっかり伝わっているか
リテンション(Retention) 使い続けてくれるくらい、製品の価値に満足してるか
レファラル(Refallal) 友人に伝えたくなるほど満足してるか
レベニュー(Revenue) お金を払ってくれるほど製品の価値に満足してくれているか
アクイジション(Aquisition) 製品の価値を広めるために、正しいチャネル・訴求軸を選べているか
であるとのことでした。
体感的には最初のActivationとRetensionが重要でこの2フェーズに注力すれば残り3フェーズは勝手に結果がついてきているとのこと。
では実際にミクロレベル(実務レベル)に落とし込んでARRRAモデルを行うとすると何をするべきか?ということで、ミクロレベルの話ではアクティベーションのフェーズに絞ってお話がありました。
ミクロレベルの話
アクティベーションのフェーズで行うべきことはプロダクト開発前とプロダクト開発後で異なってくるのだそうです。
すなわち、
・プロダクト開発前はプロブレムソリューションフィット(PSF)、要するに誰の何をどうやって解決するのか、そもそも課題が存在しているのかの検証を重視する。
・プロダクト開発後はユーザーオンボーディング、プロダクトを使ってもらってこのサービスめっちゃいい!て思ってもらうことを重視する。
ということでした。順番に見ていきましょう。
アクティベーションの前行程(プロダクト開発前)
まず、プロダクト開発前はPSFのために課題が存在し、顧客がそのプロダクトを求めている証拠を事前に得ることが重要だそうです。
ここで事例としてZapposという靴のECを初めて行ったサービスについて話がありました。
アメリカでは靴を買いたい人が、わざわざそれを買いに行くのは土地が広くて大変だし、セールもきいていないから高い。そこでZapposの創業チームはECで靴を販売すれば売れるのではないか?というアイデアを持っていました。しかし、本当にオンラインで靴が売れるのかが心配されていた。
そこで創業チームはまずECサイトのフロントページだけ作成し発注発送は人力でやる形でサービスを開始しました。
これによってそもそもECで靴を買ってくれる顧客が存在するかを検証し、無事多くの人がサービスを利用してくれることがわかったのでバックエンドを作り込んで行ったという事例を紹介してくれた。
実際にはここまでうまくいく話ばかりではないだろうということでVasilyで行っているジャベリンボードというフレームワークを使った仮説検証方法の紹介がありました。
ジャベリンボードは日本語で検索しても出てこないがjavelin boardで検索すると画像が出ててきます。
ここで事例としてZapposという靴のECを初めて行ったサービスについて話がありました。
アメリカでは靴を買いたい人が、わざわざそれを買いに行くのは土地が広くて大変だし、セールもきいていないから高い。そこでZapposの創業チームはECで靴を販売すれば売れるのではないか?というアイデアを持っていました。しかし、本当にオンラインで靴が売れるのかが心配されていた。
そこで創業チームはまずECサイトのフロントページだけ作成し発注発送は人力でやる形でサービスを開始しました。
これによってそもそもECで靴を買ってくれる顧客が存在するかを検証し、無事多くの人がサービスを利用してくれることがわかったのでバックエンドを作り込んで行ったという事例を紹介してくれた。
実際にはここまでうまくいく話ばかりではないだろうということでVasilyで行っているジャベリンボードというフレームワークを使った仮説検証方法の紹介がありました。
ジャベリンボードは日本語で検索しても出てこないがjavelin boardで検索すると画像が出ててきます。
こんなやつです。
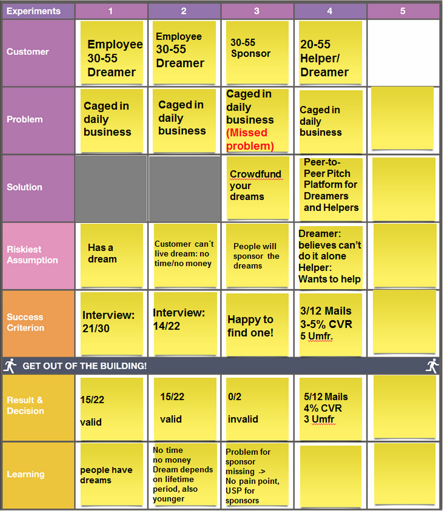
ジャベリンボードでは顧客と課題と解決方法をまず仮説として提示し、それに対するもっとも大きなリスク想定(間違っているかもしれない仮説)を考えることから始めるのだそう。
講演で挙げられていた例示だと、大学生向けの荷物預かりサービスを立ち上げようと考えている時、もっとも間違っている可能性のある仮説は一人暮らし大学生は荷物をたくさん持っているということ。(預けるほどたくさんの荷物をもっている学生はほとんどいない、ということがもっともリスキーな想定となる)
これに関して質問方法と仮説が正しいか検証するための判断基準をまず書いていく。
ここでは一人暮らし大学生に荷物が家の何%を占めているかを聞き、80%を占めている大学生が10人中6人いたらその課題は存在すると結論づける、としていました。
さらに下のセルの結果と判断では、検証結果や検証を通して学んだことを書いていく。
最初の仮説はほとんど外れているため、顧客や課題、解決方法などを更新して二回目の最大リスク想定、検証、結果確認といった形で、検証の結果、その課題が存在するという判断ができるまで仮説を反復的に磨き上げるということをVasilyでは行っているそうです。
アクティベーションの後工程(プロダクト開発後)
プロダクトができあがったあとのアクティベーションでは使ってもらってこのサービスいい!とすぐに思ってもらうことが大事で、それを実行するための考え方としてユーザーオンボーディングというものがあるのだそう。ユーザーオンボーディングは下記に挙げる3つの要素からなっている。
① ヴァリュープロポジション
プロダクトがどのような価値を提供するのか、わかりやすく伝えること。
ランディングページなどでそのサービスの本質的な価値を説明する、といった方法がある。
たとえばPinterestはLPでユースケースを伝えることで、ユーザーがPinterestを使ってどんなことができるか、どんな体験が得られるかを表示している。
たとえばこんな感じ
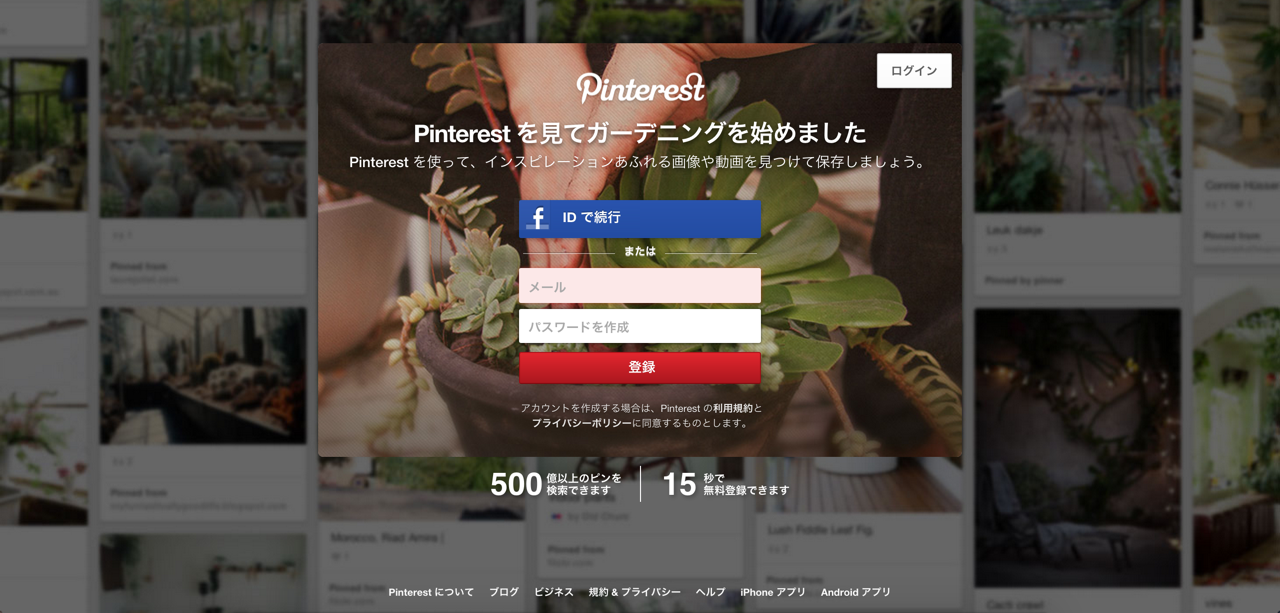
② 利用方法の理解
どんなに価値のあるサービスでもユーザーがそのサービスの使い方を理解できなければ意味がない。
ユーザーがサービスの使い方を簡単に理解できるような何かが必要。
使い方の説明であったり、チュートリアルを自分で操作できるインタラクティブデモがこれにあたる。
③ Aha体験
実際のサービス利用開始後数アクションでこのサービスいい!と思わせること。
Twitterは登録と同時に5人フォローさせることで、開始後すぐにTwitterのよさを理解してもらう戦略をとっているというのは有名な話。
以上3点であげたような要素がユーザーオンボーディングの要素として重要で、
Vasilyではグロースキャンバスというフレームワークを使ってユーザーオンボーディングを達成しようとしている。
斜めからの画像で申し訳ないのですが、こんな感じの独自フレームワークを作成して使用しているのだそうです。
グロースキャンバスのフレームワーク画像

使い方は、まず右上の鍵となる指標を決めてから定性的な分析と定量的な分析を行って最初の発見(5×6の正方形の一番左上)に記入できる気づきを探すことから始める。
たとえばVasilyのプロダクトであるiQONで今までよりユーザーの再訪率を高めたいとしたら、
・定量的な分析では初回登録から引き続き使用してくれているユーザーのデータと、逆に初回登録から使用してくれていないユーザーのデータを確認することで気づきを探していく(ずっと使用してくれている人の共通点と、あるいは逆に初回登録以降使用してくれていないユーザーの共通点を分析するということだと思われる)。
・定性的な分析では初回登録から引き続き使用してくれているユーザーへのインタビュー、逆に初回登録から使用してくれていないユーザーへのインタビューによって気づきを探していく。
・発見した気づきに関してはフレームワーク右上の、4象限のに別れた部分に一つ一つプロッティングしていく。
4つの象限を分割している二軸は、画像には記入されていないが縦軸は再現性、横軸はそれが実現された時のインパクトを表していて、再現性とインパクトが大きい順に重要度が高い気づきとしてフォーカスする、といった感じで使うそうです。
続いて発見した気づきに関して、表中央から下の発見、因果関係、MVP、評価指標、計測結果の部分を順次埋めていくことで検証を行っていくのがフレームワークの下側。
たとえば、再現性とインパクトが優れていた気づきとして「再訪してくれる人はコーディネイトを1件アップロードしてくれている」といったものがあったとする。
まずはこの気づきに対して再訪とコーディネイト一件作ってもらうことの間の因果関係を分析する(コーディネイトを作ってくれたから再訪してくれたのか、逆にそもそも再訪してくれるぐらい熱心な人だからコーディネイトを投稿してくれたのか。あるいは因果関係は存在せず相関があるだけなのか)。
これを確かめるためのMVPとして登録時にコーディネイトを一つ投稿することを強制する機能を実装し、一週間後の残存率を計測する形で仮説を検証する。
もし残存率が予想を下回っていたら仮説が間違っていたということであり、発見をアップデートする(フレームワークでいうと、右側にいっこずらして同じように記述をしていく。「他の人のコーディネイトを見て、自分でもコーディネイトを作ってくれているひとは再訪している」など)。
以上のようなフレームワークなどを駆使して因果関係をハック、検証してして本質的なグロースハックをしよう!
ということでした。